Use pretokenized text with Huggingface transformers
For seqviz and INCEpTION external recommender, I recently had the problems that I needed to use BERT for sequence tagging but needed to predict labels for my own tokens. The problem is that transformers typically use subword tokenization like WordPiece or Sentence piece. That means, one of my tokens potentially has more than one transformer token.
The trick to align the two tokenizations is the following: one does not ask the transformer tokenizer to tokenize the whole sentence, but let the tokenizer tokenize each of your tokens. This allows us to know which token mapped to which group of transformer tokens.
My Python implementation goes as follows:
We first import the HuggingFace transformers package and set up our model together with the tagset.
from collections import Counter
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
label_list = [
"O", # Outside of a named entity
"B-MISC", # Beginning of a miscellaneous entity right after another miscellaneous entity
"I-MISC", # Miscellaneous entity
"B-PER", # Beginning of a person's name right after another person's name
"I-PER", # Person's name
"B-ORG", # Beginning of an organisation right after another organisation
"I-ORG", # Organisation
"B-LOC", # Beginning of a location right after another location
"I-LOC" # Location
]
As an example sentence, we use the NER example sentence of Huggingface and simulate external tokenization by just splitting on whitespace.
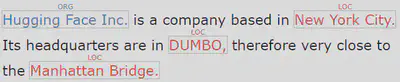
text = "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very close to the Manhattan Bridge."
my_tokens = text.split()
The next step is to tokenize the input and group subtokens. For every of our tokens, we tokenize. We manually need to add the special [CLS] and [SEP] tokens. The result is a list with grouped subtokens and another which contains the information how many subtokens each token has. To make the inputs usable for our model, we need to flatten the grouped subtoken list.
grouped_inputs = [torch.LongTensor([tokenizer.cls_token_id])]
subtokens_per_token = []
for token in my_tokens:
tokens = tokenizer.encode(
token,
return_tensors="pt",
add_special_tokens=False,
).squeeze(axis=0)
grouped_inputs.append(tokens)
subtokens_per_token.append(len(tokens))
grouped_inputs.append(torch.LongTensor([tokenizer.sep_token_id]))
flattened_inputs = torch.cat(grouped_inputs)
flattened_inputs = torch.unsqueeze(flattened_inputs, 0)
We use these inputs to predict and convert from label ids to our string labels.
predictions_tensor = model(flattened_inputs)[0]
predictions_tensor = torch.argmax(predictions_tensor, dim=2)[0]
predictions = [label_list[prediction] for prediction in predictions_tensor]
The next step is to align our tokenization with the predictions we just made. First, we remove the predictions for the special tokens. We previously computed how many subtokens belong to each of our tokens.
predictions = predictions[1:-1]
aligned_predictions = []
assert len(predictions) == sum(subtokens_per_token)
ptr = 0
for size in subtokens_per_token:
group = predictions[ptr:ptr + size]
assert len(group) == size
aligned_predictions.append(group)
ptr += size
assert len(my_tokens) == len(aligned_predictions)
The result is a list which contains for every token the predictions for its subtokens. Predictions for a group of subtokens do not need to be necessarily the same. For instance, the transformer tokenizer creates two subtokens out of a word which has punctuation. The punctuation is labeled O while the rest is labeled ORG. In our example, we just perform majority voting:
for token, prediction_group in zip(my_tokens, aligned_predictions):
label = Counter(prediction_group).most_common(1)[0][0]
print("{0:>12}\t{1:>5}\t{2}".format(token, label, prediction_group))
The result is
Hugging I-ORG ['I-ORG', 'I-ORG']
Face I-ORG ['I-ORG']
Inc. I-ORG ['I-ORG', 'O']
is O ['O']
a O ['O']
company O ['O']
based O ['O']
in O ['O']
New I-LOC ['I-LOC']
York I-LOC ['I-LOC']
City. I-LOC ['I-LOC', 'O']
Its O ['O']
headquarters O ['O']
are O ['O']
in O ['O']
DUMBO, I-LOC ['I-LOC', 'I-LOC', 'I-LOC', 'O']
therefore O ['O']
very O ['O']
close O ['O']
to O ['O']
the O ['O']
Manhattan I-LOC ['I-LOC']
Bridge. I-LOC ['I-LOC', 'O']
which looks with seqviz like
You can find the full code in this Gist.